
环境:
elasticsearch 7.6
logstash 7.6
kibana 7.6
背景:
当我们在kibana 查找搜索日志的时候可以直接搜索关键字去查找日志,但是有时候我们查一些关键字的时候发现无法查到,明明日志里面包含这个关键字但是就是查不到,这是为啥呢,在此我们引入一个关键词Analysis
Analysis 我们可以叫它分词器,那么有啥作用呢?简单点说就是针对一段文本进行词组,单词,字符等等,进行拆分标记的一种工具,它拆分出来的我们就可以进行关键词的搜索了。点击Analysis 进入官网查看完整的介绍;
既然知道了我们搜索的关键词是靠分词器分出来的,那就好办了,官方的自定义分词器显然不能满足一些特殊场景的需求,所以我们自定义分词器进行分词。
需要进行分词的测试文本:java.lang.NullPointerException: null at com.xxx.xxxxx-xxxx.xxx<123>sss.(666)ssss$ffff#oooo&iiii_yyy;kkk=lll!eeee`qqqq%aaaa?rrr
第一步:测试分词器
打开kibana的dev tools工具,在控制台写入自定义的规则,例:
PUT test_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "pattern",
"pattern":["\\."," ","\\","。","\\:","\\-",",","(",")","[","]","{","}","#","$","%","&","!","^","`","/","+","=","_","?",">","<","\\;"]
}
}
}
}
}
解释一下:
PUT test_index 就是创建一个新的索引,名字叫test_index.
analysis :创建一个过滤器
my_analyzer:自定义的分析器名字
my_tokenizer:自定义分词器规则的名字
type:分析器类型,包括keyword;pattern;simple_pattern;char_group;simple_pattern_split;path_hierarchy.本次使用pattern :使用正则表达式在匹配单词分隔符时将文本分割成关键字,或者捕获匹配的文本作为分词标记。具体参考:Tokenizers
pattern:后面写的就是用来分词的标记了,有些字符是特殊的比如英文的 “.” “-“这种特殊的字符如果想作为分词的标记可以用双斜线\\进行转义。那如果想用\作为分隔符呢?\\即可。上面例子中引号内的全部作为分词标记使用,当然可以增加你自己的或者减少不需要的。
点击旁边的运行按钮生成这个新的索引如图:

第二步:进行测试
用我们测试文本进行测试:
POST test_index/_analyze
{
"analyzer": "my_analyzer",
"text": "java.lang.NullPointerException: null at com.xxx.xxxxx-xxxx.xxx<123>sss.(666)ssss$ffff#oooo&iiii_yyy;kkk=lll!eeee`qqqq%aaaa?rrr"
}
analyzer: 引入我们刚刚创建的分析器。
text:测试文本的内容
执行结果如图:
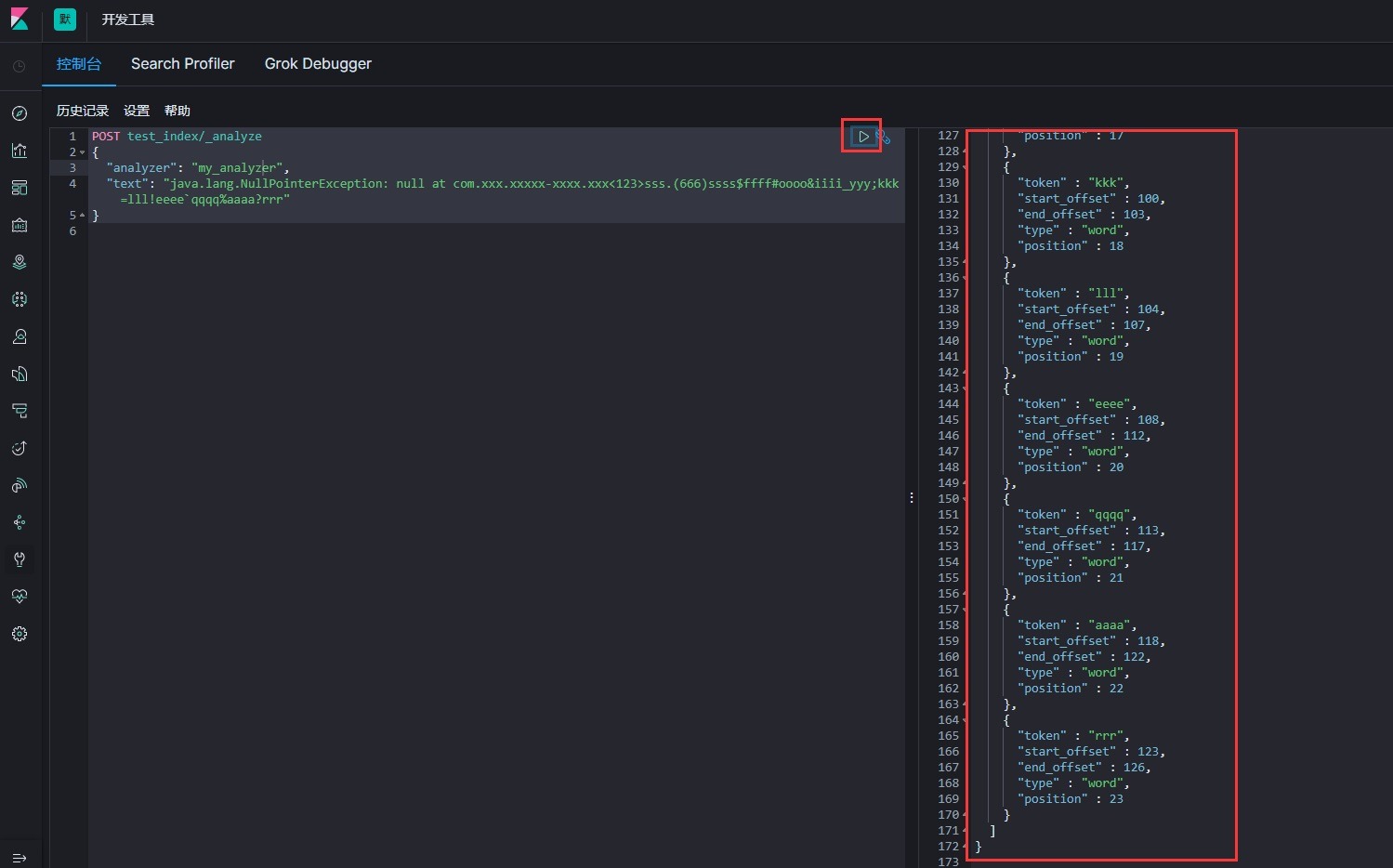
成功的按照我们定义的标记分开了,
分词成功了 那么怎么去让当前的索引生效呢?
第一种:
直接将之前索引的数据全部迁移到新建的这个索引中来,这样比较浪费时间。但是所有的数据分词都会生效。可以用
elasticdump elasticsearch-head 差件。
第二种:
直接修改当前的索引模板,但是已经存储的索引数据不会生效,后续根据这个模板新增的索引会生效。
我用的这种方法。顺便推荐个es集群管理工具(非常方便的工具):cerebro
可以直接修改索引模板文件不需要重启,当然直接去各节点服务器改模板文件也行。直接去服务器修改可能要重启吧。
在模板配置中的setting内增加分词器配置
{
"test" : {
"order" : 0,
"index_patterns" : [
"test-*"
],
"settings" : {
"index" : {
"analysis" : {
"analyzer" : {
"my_analyzer" : {
"tokenizer" : "my_tokenizer"
}
},
"tokenizer" : {
"my_tokenizer" : {
"pattern" : [
"\\.",
" ",
"\\-"
],
"type" : "pattern"
}
}
}
}
},
"mappings" : {
"properties" : {
"@timestamp" : {
"type" : "date"
},
"log_test" : {
"analyzer" : "my_analyzer",
"type" : "text"
},
"logs" : {
"analyzer" : "my_analyzer",
"type" : "text"
}
}
},
"aliases" : { }
}
}
setting中为新增的分词器配置,
mapping中的是指定哪些字段使用哪个分词器。不指定默认使用es的标准分词器。

使用cerebro工具修改的样例:
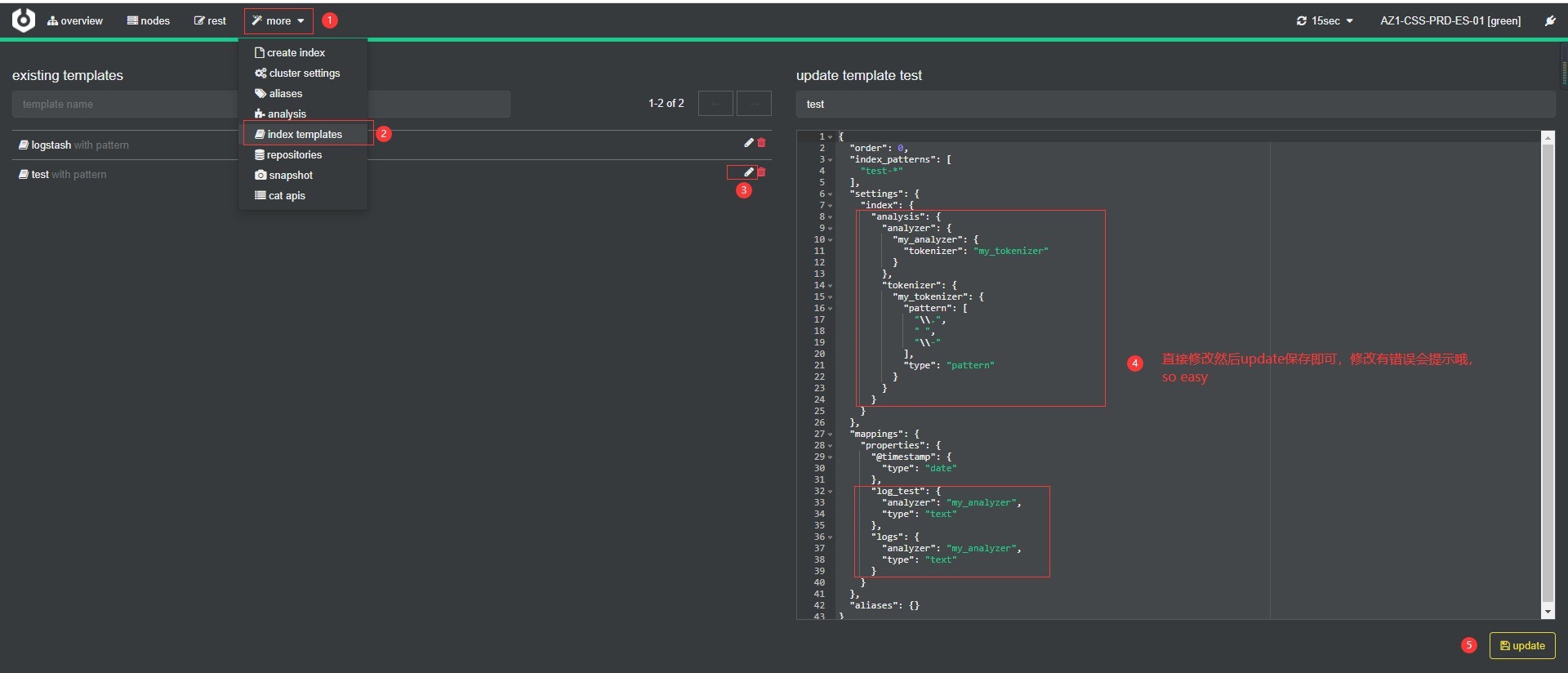
图片看不清楚可以在右键在新的标签页打开查看会更清晰

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~

