
Federation(联邦)概述:
- 通常,它用于实现可扩展的 Prometheus 监控,从一个 Prometheus服务中提取相关指标进入另一个Prometheus服务。简单点理解就是吧其他prometheus服务收集到的指标数据汇总到一台主promettheus中。
- 在跨服务联合中,配置一个服务的 Prometheus 服务器 从其他服务的 Prometheus 服务器抓取选定的数据以启用针对单个服务器中的两个数据集发出警报和查询。例如,运行多个服务的集群计划程序可能会公开 有关服务实例的资源使用情况信息(如内存和 CPU 使用情况) 在群集上运行。另一方面,在该群集上运行的服务 将仅公开特定于应用程序的服务指标。通常,这两组 指标由单独的 Prometheus 服务器抓取。使用联合, 包含服务级别指标的 Prometheus 服务器可能会拉入集群 来自集群 Prometheus 的有关其特定服务的资源使用指标, 以便可以在该服务器中使用这两组指标。
使用场景:
多个数据中心或者多个系统分别安装了prometheus,想要将这些监控指标汇集到一起进行展示存储。本次以k8s集群进行举例,目前有多个k8s集群环境,每个集群中都安装了kube-prometheus服务,我们要实现的就是将这些集群的指标全部汇总到一台prometheus监控服务器中。
当前环境:
- 多套k8s集群,均安装了kube-prometheus服务,未安装可参考:K8s安装prometheus监控 – woniusnail
- 本地部署了一套prometheus+alertmanager ,未安装可参考:Prometheus+Grafana+Alertmanager实现监控+告警通知 – woniusnail
联邦配置:
-
修改services,暴露出k8s中prometheus-的端口,确保本地的prometheus能够链接
-
获取k8s中prometheus配置文件job名字,直接查看配置文件或参考以下内容获取
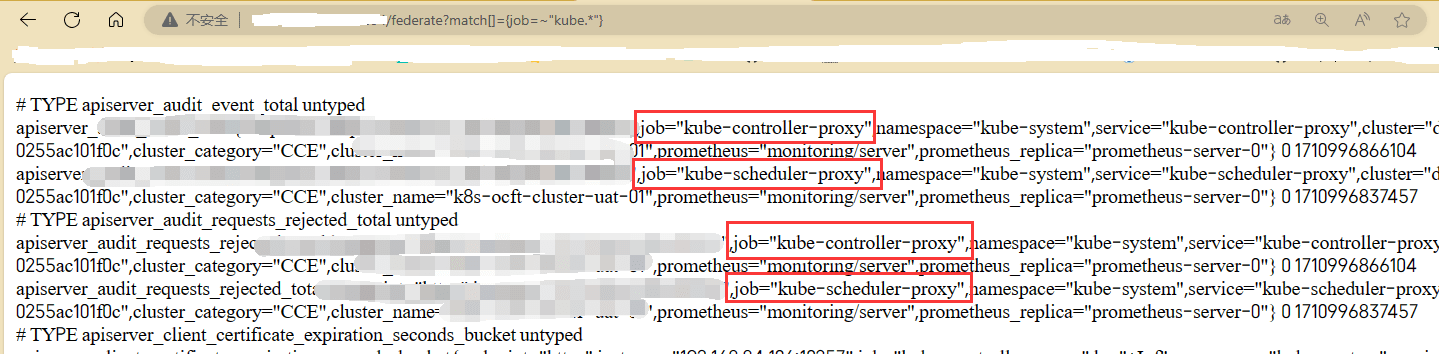
浏览器或者postman访问:192.168.10.30:32090/federate?match[]={job=~”kube.*”}
解释:
- 192.168.10.30:32090 :通过service从k8s映射出来的prometheus访问地址
- /federate:就是联邦的默认访问接口
- match[]={job=~”kube.*”} :匹配规则,固定格式其中job=~”kube.*”就是匹配访问集群中所有以kube开头的job名字,如果不清楚都有哪些job可以直接改成job=~”.*”,然后根据结果获取job名字再进行下一步。
- 例:
3. 修改本地的prometheus配置文件
...
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
#- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
- job_name: 'kubernetes'
scrape_interval: 15s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job=~"jvm.*"}' #自己定义的job名字
- '{job="apiserver"}' #自己定义的job名字
- '{job=~"kube.*"}' #自己定义的job名字
- '{job="coredns"}' #自己定义的job名字
- '{job=~"etcd.*"}' #自己定义的job名字
- '{job="node-exporter"}' #自己定义的job名字
- '{job="prometheus-server"}' #自己定义的job名字
#- '{job=~".*"}' #不建议使用这个,根据第2步找出对应的job填写。
- '{__name__=~"job:.*"}'
file_sd_configs:
- files:
- "/volumes01/prometheus/kubernetes/kubernetes.yaml" #指定读取的配置文件实现热加载。
refresh_interval: 10s
...
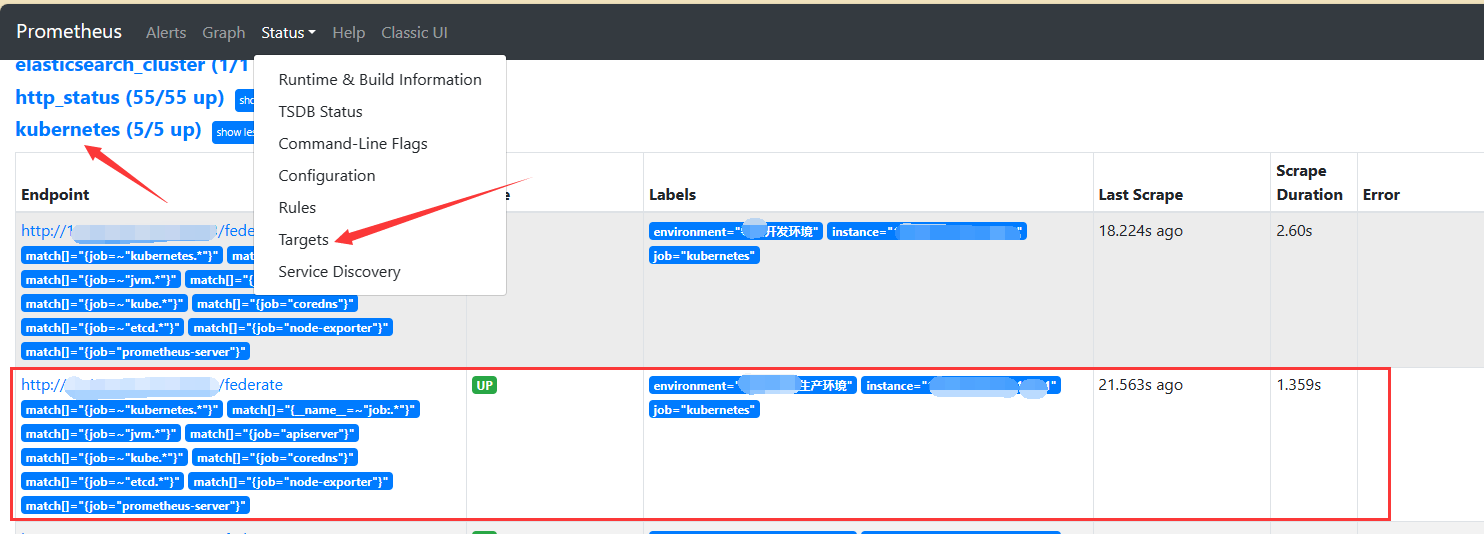
4.重启或者重载本地prometheus配置后查看本地prometheus的target界面

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~

